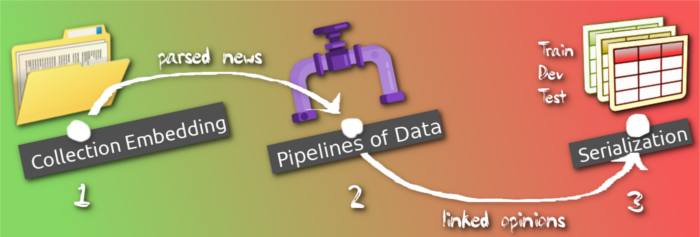
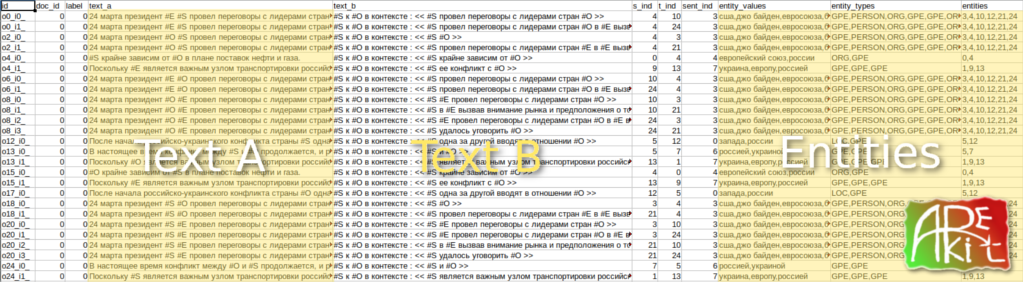
Visa Granted but Working permission Refused: 76 days of limbo or ATAS adventures
Picture: Observation wheel of the new spot 🎡 or such an adventure traits?
When contranct is about to over or any other circumstaces sings to its termination, it becomes a time of personal iterest in eligibility of your further rights to work and stay in country. In some cases it might be just a simple switch to another position, but in others causes to issue a new VISA.