Automatic processing of a large documents requires a deep text understanding, including connections between objects extraction. In terms of the latter and such domain as Sentiment Analysis, capturing the sentiments between objects (relations) gives a potential for further analysis, built of top of the sentiment connections:

In this post we’re focusing on the Sentiment Relation Extraction between mentioned entities in texts, written in Russian. This analysis finds its application in analytical texts, in which author sharing his opinion onto variety of objects. The latter causes some text objects to become a source of opinions in texts. More onto the related task could be found in this paper or at NLP-progress.
For this Sentiment Relation Extraction we adopt and design AREkit framework (0.22.0). Let’s take a closer look on how this framework (set of toolkits) allows us to prepare the information in order to initiate automatic relation extraction by means of machine learning methods. In particular, within this post we are focused on BERT language models.
All the snippets below organized in a example (unit-test script) withing a side project dubbed as ARElight which may be found here.
Here, we start by declaring a list of texts it is expected to be processed. In particular we consider a list of a single document:
texts = [
# Text 1.
"""24 марта президент США Джо Байден провел переговоры с
лидерами стран Евросоюза в Брюсселе, вызвав внимание рынка и предположения о
том, что Америке удалось уговорить ЕС совместно бойкотировать российские нефть
и газ. Европейский Союз крайне зависим от России в плане поставок нефти и
газа."""
]
Next, we declare a synonyms collection.
It is provided by AREkit and allows us to address on the named entity co-reference problem.
In order to initialize this collection, there is a need to provide a list of synonym groups
(see an example).
Since the entity values are in russian, it expected to represent them in a lemmatized format.
For the latter we adopt a wrapper over mystem (MystemWrapper) library.
While using synonyms collection, it is expected that in some cases entries might not be found
and therefore we allow synonyms collection expansion by treating it in a non read-only mode
(is_read_only flag is False).
synonyms_filepath = "synonyms.txt"
def iter_groups(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
for data in iter_synonym_groups(file):
yield data
synonyms = StemmerBasedSynonymCollection(
iter_group_values_lists=iter_groups(synonyms_filepath),
stemmer=MystemWrapper(),
is_read_only=False,
debug=False)
On the second step, we implement text parser. In AREkit-0.22.0, the latter represents a list of the transformations organized in a pipeline of the following transformations:
- We split the input sequence onto list of words separated by white spaces.
- For named entities annotation we adopt BERT model (pretrained on the OntoNotes-v5 collection), provided by DeepPavlov.
- Since we perform entities grouping, there is a need to provide the related function (
get_synonysms_group_index):
def get_synonym_group_index(s, value):
if not s.contains_synonym_value(value):
s.add_synonym_value(value)
return s.get_synonym_group_index(value)
text_parser = BaseTextParser(pipeline=[
TermsSplitterParser(),
BertOntonotesNERPipelineItem(lambda s_obj: s_obj.ObjectType in ["ORG", "PERSON", "LOC", "GPE"])
EntitiesGroupingPipelineItem(lambda value: get_synonym_group_index(synonyms, value))
])
Next, we declare the opinion annotation algorithm required to compose a PAIRS of objects
across all the objects mentioned in text.
All the pairs are considered to be annotated with the unknown label (NoLabel).
In addition, it is possible to clarify the max distance bound in terms between pair participants, or leave it None
by considering a pair without this parameter:
algo = PairBasedAnnotationAlgorithm(
label_provider=ConstantLabelProvider(label_instance=NoLabel()),
dist_in_terms_bound=None)
annotator = DefaultAnnotator(algo)
Then, we focusing on experiment context implementation.
- Declare a folding over list of documents.
In general, you may organize a split of document onto
TrainandTestsets. Within this example, we adoptNoFoldingand consider that all the documents will be witin a single (DataType.TEST) list. - Declare labels formatter, which is required for
TextBof the BERT input sequence in further. - Declare entities formatter, considering masking them by providing a BERT styled, sharp-prefixed tokens:
#O(Object) and#S(Subject).
no_folding = NoFolding(doc_ids_to_fold=list(range(len(texts))),
supported_data_types=[DataType.Test])
labels_fmt = StringLabelsFormatter(stol={"neu": NoLabel})
str_entity_formatter = SharpPrefixedEntitiesSimpleFormatter()
On last prepartion step, we gather everyting together in order to compose an experiment handler.
Being a core module of AREkit, experiment – is a sets of API components required to work with a large amount of mass-media news. This set includes and consider initialization of the following components:
- context – required for sampling. (BertSerializationContext)
- input/output – methods related to I/O operations organization (InferIOUtils)
- document related operations (CustomDocOperations);
- opinion related operations;
- BaseExperiment – exposes all the structures declared in 1-4.
- List of handlers.
For context initialization:
- Contexts with a mentioned subject object pair in it, limited by
50terms; NoLabel()instance to label every sample.
exp_ctx = BertSerializationContext(
label_scaler=SingleLabelScaler(NoLabel()),
annotator=annotator,
terms_per_context=50,
str_entity_formatter=str_entity_formatter,
name_provider=ExperimentNameProvider(name="example-bert", suffix="serialize"),
data_folding=no_folding)
exp_io = InferIOUtils(exp_ctx=exp_ctx, output_dir="out")
doc_ops = CustomDocOperations(exp_ctx=exp_ctx, text_parser=text_parser)
opin_ops = CustomOpinionOperations(labels_formatter=labels_fmt,
exp_io=exp_io,
synonyms=synonyms,
neutral_labels_fmt=labels_fmt)
exp = BaseExperiment(exp_io=exp_io,
exp_ctx=exp_ctx,
doc_ops=doc_ops,
opin_ops=opin_ops)
For the mentioned classes above we left the implementation details behind from this post.
In terms of experiment handler, which is related to data preparation for BERT model, additionally declaring:
nli-mtext formatter forTextBand utilize NLI approach by empasizing the context between Object and Subject pair (see original paper).
handler = BertExperimentInputSerializerIterationHandler(
exp_io=exp_io,
exp_ctx=exp_ctx,
doc_ops=doc_ops,
opin_ops=exp.OpinionOperations,
sample_labels_fmt=labels_fmt,
annot_labels_fmt=labels_fmt,
sample_provider_type=BertSampleProviderTypes.NLI_M,
entity_formatter=exp_ctx.StringEntityFormatter,
value_to_group_id_func=synonyms.get_synonym_group_index,
balance_train_samples=True) # This parameter required by not utilized.
NOTE: In further versions we’re looking forward to adopt dictionaries to pass these parameters, see issue #318
The application of the handler towards the provided lists of texts is based on the ExperimentEngine.
The engine allows to execute handler by passing a folding schema.
we adopt experiment engine:
def input_to_docs(texts):
docs = []
for doc_id, contents in enumerate(texts):
sentences = ru_sent_tokenize(contents)
sentences = list(map(lambda text: BaseNewsSentence(text), sentences))
doc = News(doc_id=doc_id, sentences=sentences)
docs.append(doc)
return docs
docs = input_to_docs(texts)
doc_ops.set_docs(docs)
engine = ExperimentEngine(exp_ctx.DataFolding) # Present folding limitation.
engine.run([handler])
NOTE: We demonstrate it in a simple way, consuming
O(N)memory (N-amount of documents). However it is possible to perform document reading on demand, to prevent keep all the document in memory.
Finally, the output represents a multiple files, including opinions, samples:
out/
opinion-test-0.tsv.gz
sample-test-0.tsv.gz <-- Required.
result_d0_Test.txt
NOTE: Other files generated after handler application are not utlized within this example and might be removed in future AREkit releases. see #282
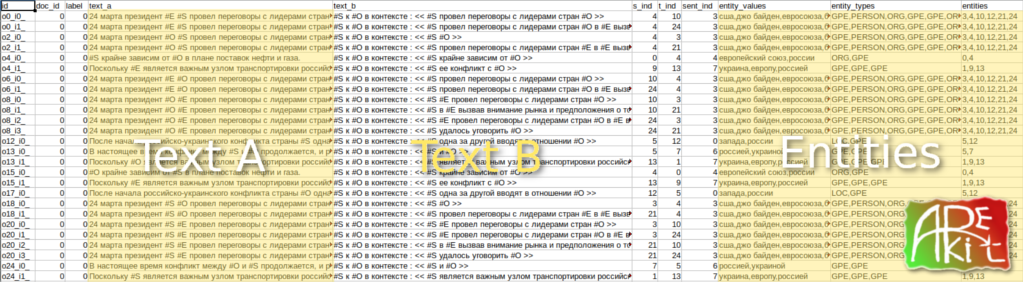
As a result (another output example), every sample consist of the following fields:
id– row identifierdoc_id– document identifierlabel– sample labeltext_a– TEXT_A of the input sample context for BERT model (before[SEP]).text_b– TEXT_B, utilized fornliextra sentence (after[SEP])s_ind– term index of theSubjectin text (#S)t_ind– term index of theObjectin text (#0)sent_ind– sentence index in the related documententity_values– entity values (in order of their appearance in sample)entity_types– entity types (in order of their appearance in sample)
NOTE: Now we have a fixed set of columns declared in
handler. We looking forward to provide a customization and make API even more flexible.
Thank you for reading this tutorial, related to the ARElight project functionality in particular. For a greater details, feel free to procced and invesigate the following repository. In next posts we provide details on how to adopt the pre-generated samples in model fine-tunning process.
References
[1]. AREkit – is an Attitude and Relation Extraction toolkit
[2]. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[3]. Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence