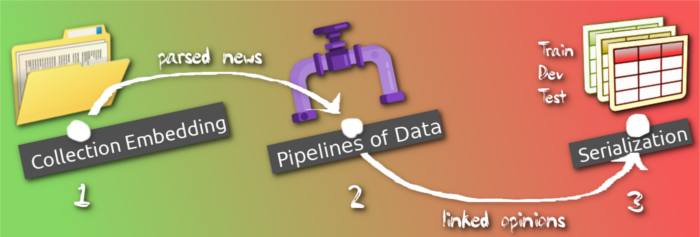
We are finally ready to annonce the workflow of data-processing organization in AREkit for sampling laa….aaarge collection of documents!
Here, the Laa....aarge denotes that the whole workflow could be treated as iterator of document collection.
At every time step we manage information about only a single document of the whole collection which allows us to avoid out-of-memory exceptions.
The workflow, illustrated on figure above, consider three main stages:
First, it is necessary to bind your collection by implementing the related API, in order to provide information about relations of every document. The binded collection provides the following information for a given text:
- list of annotated objects in it (entities, events, etc.)
- list of the relations – connections between objects
Second, you are able adopt text-processing pipelines, including:
- Text processing it-self, i.e. objects annotatin, frame-entries annotation, tokenization, and lemmatization
- Extract text-opinions, i.e. instances which describes connections between mentioned objects in texts.
The last step we provide the details on how to perform data-serialization depending on the our Machine Learning model expectations, i.e.:
- Classic neural networks: convolutional, recurrent, etc.
- Transformers, BERT
Next, we are head to provide the tutorials on every step of the workflow. Checkout the further posts for a greater details on so.
Thank you for reading!