
Figure: Results of an automatic sentiment relation extraction between mentioned named entities from Mass-Media Texts written in Russian. Visualized with BRAT Rapid Annotation Tool.
Sentiment attitude extraction [6] – is a sentiment analysis subtask, in which attitude corresponds to the text position conveyed by Subject towards other Object mentioned in text such as: entities, events, etc.
In this post we focused on the sentiment relation extraction between mentioned named entities in text, based on sampled contexts of Mass-Media news written in Russian. In terms of sentiments, we focused on two-scale sentiment analysis problem and consider: positive and negative attitudes. Samples were generated by AREkit and then utilized for BERT classification model training by means of DeepPavlov framework.
For a greater details related to samples preparation details, please follow the related post Process Mass-Media relations for Language Models with AREkit.
In this article we focusing on already prepared contexts from RuSentRel collection.
Figure below illustrates an example of sampled contexts of Mass-Media texts written in Russian, utilized for finetuning.
Structurally, sampled contexts are stored in form of CSV file, in which every row represents a context from a document.
Context – is a sentence part with mentioned subject-object pair in it, where #S and #O corresponds to subject and object respectively.
Each context may have a label which could be one of the following: positive (1), negative (2), or neutral (0).
Neutral class has been artificially invented in order to illustrate the absence of sentiment connection between
subject-object pair.
Every context representation is designed for BERT model input format and describes a couple input parts: text_a and text_b.
We utilize text_b as a prompt
that allows emphasize the presence of subject-object pair in context.
In this example we focused on a predefined prompt, dubbed as nli-m [7].
As subject and object values, all the mentioned named entities are considered to display hidden and denoted as #e.
All the entity-related information were demarcated into other CSV columns (see entities group of columns in figure below).

Traning BERT for samples classification
In this section we provide short code snippets onto BERT-model training organization with DeepPavlov library. The code presented in a snippets below could be manually executed within the following examples:
Let’s get started with the required data preparation stage, which includes:
- input data preparation (RuSentRel collection processing)
- BERT pretrained model state
As for text samples, we consider the contents of RuSentRel collection which represents
analytical articles from insomi.ru portal, written in Russian.
As for the BERT initial state, we consider BERT-base-mult (multilingual, base-sized model) which
has been finetuned with texts and news titles from RuAttitudes-2.0-Large collection.
The latter represents a distant-supervision approach (knowledge-based, see paper [5])
towards mass-media collection of news.
RuAttitudes includes ~135K news with annotated attitudes between mentioned named entities.
For a greater details please proceed with the related [3].
The first step is to download the RuSentRel prepared samples for BERT model training.
Next setup BERT-pretrained state.
This is a SentRuBERT [4] model finetuned with the RuAttitudes-2.0-Large collection.
The input data represents and archive of the CSV formatter list of input contexts:
# Declaring input-related parameters.
input_data = "sample-train-0.tsv.gz"
The initial step model is to provide references onto files of the BERT state:
# Declaring BERT state related parameters.
model_dir = "./ra-20-srubert-large-neut-nli-pretrained-3l"
bert_config_file = join(model_dir, "bert_config.json")
bert_ckpt_file = join(model_dir, "model.ckpt-30238")
vocab_file = join(model_dir, "vocab.txt")
do_lowercase = True
# Training parameters.
epochs_count = 4
batch_size = 2
In order to perform samples classification, we adopt BERT classifier (bert_classifier) from DeepPavlov (0.11.0) library.
According to the personal experience, It is was important to mention here a load path parameter: load_path=model_checkpoint_path.
Since only the latter allows to perform a complete model loading, including the classification layer ontop of the BERT backbone.
# Model classifier.
model = bert_classifier.BertClassifierModel(
bert_config_file=bert_config_file,
load_path=bert_ckpt_file, # IMPORTANT: intialize classification layer!
keep_prob=0.1,
n_classes=3,
save_path="out",
learning_rate=2e-5)
# Setup processor.
bert_proc = BertPreprocessor(vocab_file=vocab_file,
do_lower_case=do_lowercase,
max_seq_length=128)
AREkit provides a BaseRowsStorage with API for samples iteration, implemented over pandas library.
The most important notion here was to perform shuffled data iteration.
Most contexts are 0-labeled, it results in conspiracy during model training.
Among all the parameters, we keep text_a, text_b and label:
def iter_batches(s, batch_size):
assert(isinstance(s, BaseRowsStorage))
data = {"text_a": [], "text_b": [], "label": []}
# NOTE: it is important to iter shuffled data!
for row_ind, row in s.iter_shuffled(): # IMPORTANT: shuffle data!
data["text_a"].append(row['text_a'])
data["text_b"].append(row['text_b'])
data["label"].append(row['label'])
for i in range(0, len(data["text_a"]), batch_size):
texts_a = data["text_a"][i:i + batch_size]
texts_b = data["text_b"][i:i + batch_size]
labels = data["label"][i:i + batch_size]
batch_features = bert_proc(texts_a=texts_a, texts_b=texts_b)
yield batch_features, labels
We track the BERT sentiment classification model finetuning as follows:
samples = BaseRowsStorage.from_tsv(input_data)
for e in range(epochs_count):
it = iter_batches(samples, batch_size)
batches = len(samples.DataFrame) / batch_size
total_loss = 0
pbar = tqdm(it, total=batches, desc="Epoch: {}".format(e), unit='batches')
for batch_index, payload in enumerate(pbar):
features, y = payload
d = model.train_on_batch(features=features, y=y)
total_loss += d["loss"]
pbar.set_postfix({
"avg-loss": total_loss/(batch_index+1)
})
At last we keep the result model state as follows:
model.save()
The result docker DEMO. You cat try process your own text.
BERT Finetuned state Analysis
Let’s take a look on how it affects on the result for the following sample:
ведя такую игру,
#Sокончательно лишилась доверия#Ои стран#E. [SEP]#Sк#Oв контексте: «#Sокончательно лишилась доверия#O» [SEP]
playing such a game,
#Sfinally lost the trust of#Oand countries#E. [SEP]#Sto#Oin context: «#Shas finally lost the trust of#O» [SEP]
As it was mentioned earlier, we adopt entity masking, by using #o, #s, and #e, in order to
deliberately make the finetuned model independent from the statistics between mentioned named entities.
In order to analyse attention weights we adopt approach, proposed in [1].
Architectually, BERT language model represents a set of individual encoder components, dubbed as heads.
Every head implements the self-attention machanism with architecture which is behind of this post,
but covered in a large details in work [8].
Our pretrained state is a BASE-sized bert model with 12 heads, where every head consis of 12 layers.
To illustrate the changes and affection of the finetunning on attention behavior,
we consider to pick a HEAD#2 of the BERT transformer for layers (from left to right): 2, 4, 8, 11.
For even more detailed analysis, please proceed with the following paper (written in Russian) [2].
For the original state (SentRuBERT):
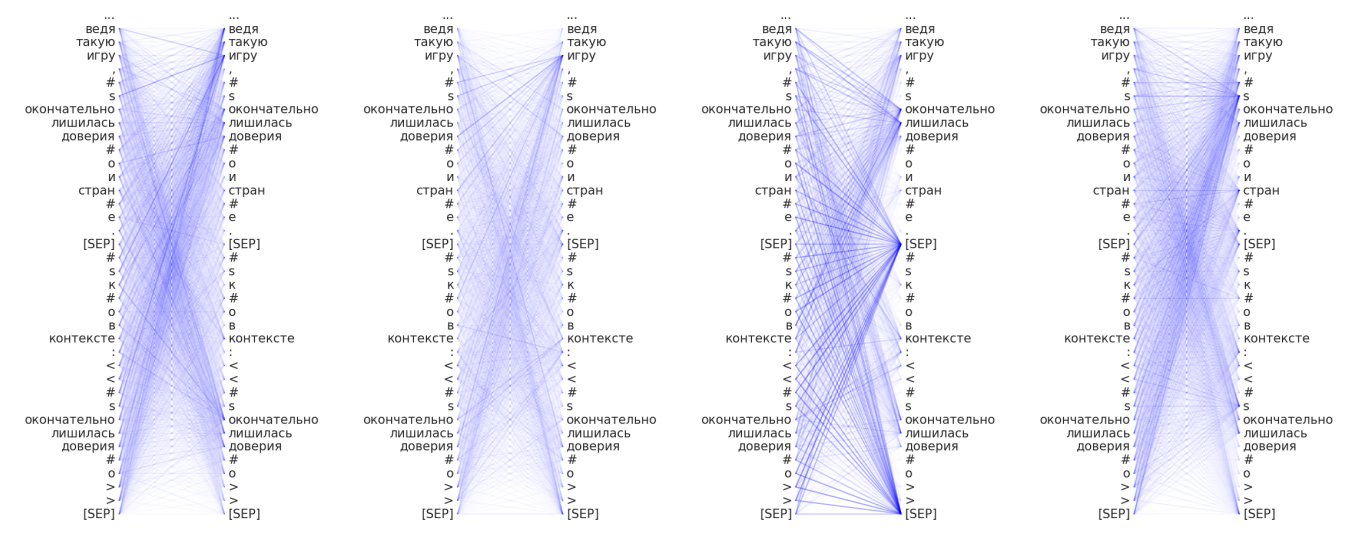
- Attention focused on the [SEP] tokens;
- Smoothed attention distribution onto the top layers (11) is a specifics of the
SentRuBERT[4] training organization.
For the initial, downloaded state (finetuned SentRuBERT on RuAttitudes-2.0-Large collection):
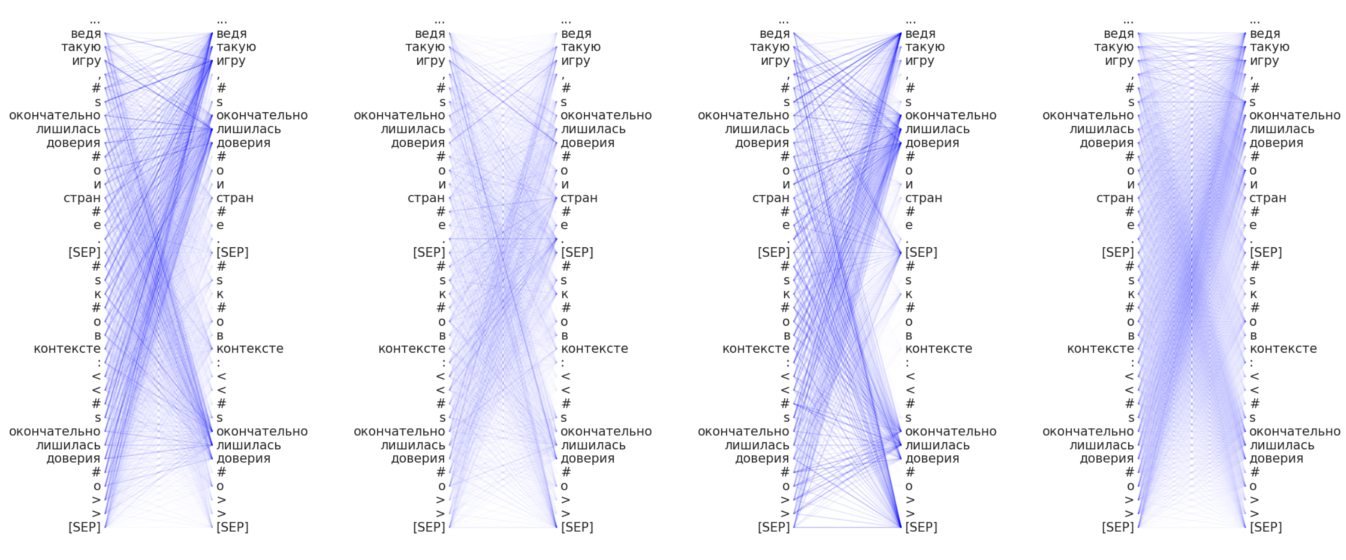
- The contents of the RuAttitudes-2.0-Large collection
yields of a large amount of news titles with annotated subject-object pairs and
mentioned frames in between them:
окончательно, (finally)лишилась, (to lost)доверия(the trust); This is caused because of the RuSentiFrames adoptation in RuAttitudes collection development: most texts represent news titles with mentioned frames in between subject-object pair.
After 4 epochs of the finetuned state (using RuSentRel collection):
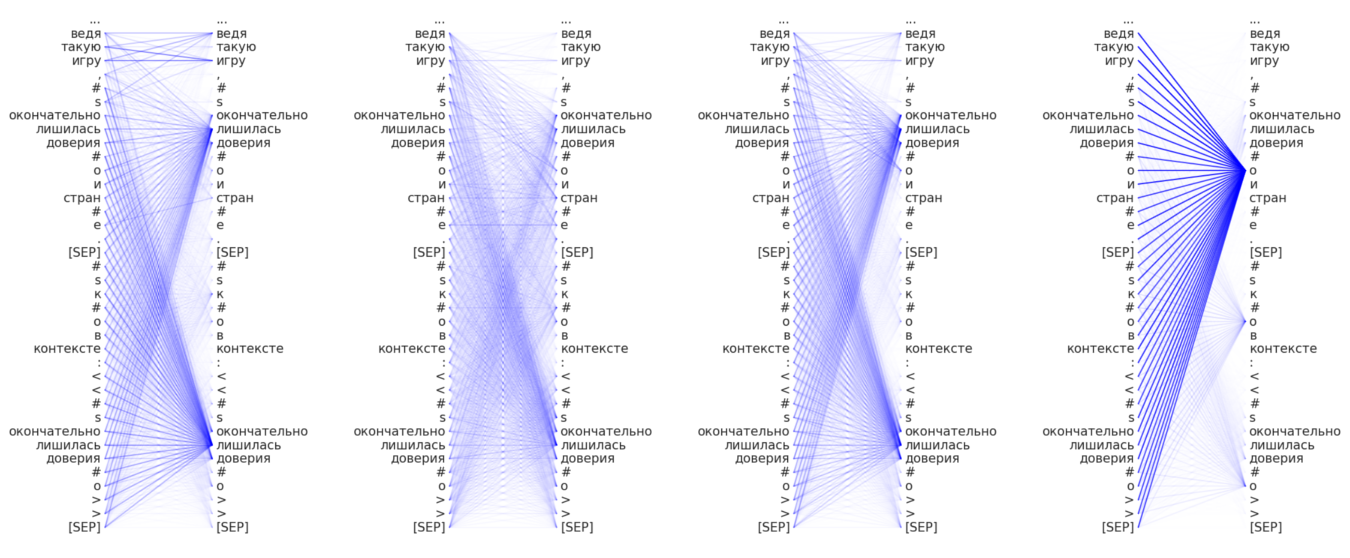
- It is possible to investigate the greater attention onto
#0and#Sobjects in sample (on top layers) - Attention become greater for frames of the
RuSentiFrames:
окончательно(finally),лишилась(to lost),доверия(the trust); the latter utlized in RuAttitudes collection development as a knowledge-base.
In the next post we cover the pre-trained model application for unlabeled Mass-Media texts using BRAT toolset as a front-end.
The latter finetuned model become a source of the following DEMO.
Summary
The most important aspects deal with once experiment with BERT application for sentiment classification task were as follows:
- Consider the classification layer hidden state loading as well
(
load_path=model_checkpoint_pathfor DeepPavlov library) - Guarantee shuffled and class-balanced input data.
References
- What Does BERT Look at? An Analysis of BERT’s Attention + [github]
- Language Models Application in Sentiment Attitude Extraction Task
- Distant Supervision for Sentiment Attitude Extraction
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- Sentiment Frames for Attitude Extraction in Russian
- Extracting Sentiment Attitudes from Analytical Texts
- Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence
- Attention is All you Need