
We are happy to announce the AREkit version 21.1.
In this post we cover the most imporant changes were done since the prior release. The complete and large list of the updates could be found on the release page.
In short we first provide greater support of the BRAT-based annotation in order to adopt it in your own collections in order to use them for attitudes annotation and document sampling for training your machine learning. We proceed to develop a toolset and treat it as a preprocessor for OpenNRE framework. OpenNRE allows you to quickly develop a model adopted for the relation extraction specific problem, by being based on the JSON-like prepared data in terms of training/fine-tunning/evaluation stages. For now, AREkit allows us to do the preprocessing work with thespecific writer.
Alongside with the AREkit, we also update the ARElight-21.1. The latter allows you to perform the quick stabilization of the input text from your console. In terms of the list of the complete changes, please follow the release notes.

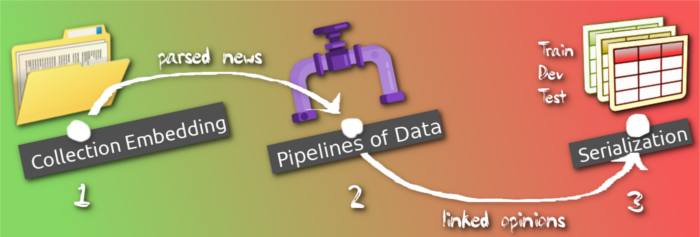
And finally we have a nice tutorials journey! (see image below) This is a list of examples over the sequence of the three major points of the application. We collect all the tutorials and separate them onto the three stage, related to:
- embedding the custom collection;
- declaration of the pipelines for
- contexts with text opinions serialization.
And all of the mentioned above does not cover all the features added so far. The complete and large list of the updates you can find on the release page in greater details.
Thank you for reading!